今天是六一国际儿童节,先祝看到这篇文章的小朋友节日快乐哈哈哈哈哈哈。
前几天和同学参加比赛,文档封面放大到A4尺寸后很模糊。
试了好几种解决方法,效果仍然不太好。
突然我灵机一动,早就听说GAN做图像生成很有东西,那就拉出来溜溜呗。
于是我用GAN,收获了大家的一致好评。



那么GAN为什么会这么强呢?且听我发表拙见。
先看这张经典的对比图。
.jpg)
左一是原图,将原图压缩,左二是用双三次插值法做插值,左三对压缩的图片用SRResNet用MSE做迭代优化,左四则是用GAN生成图像。
你可能明显看出左四的还原度是最高的。不过猛地一问为什么,你可能说不出来。其实,GAN生成的图像相较于SRResNet在细节方面更加清晰。
这是什么原因造成的呢?
其实用MSE做优化的话,为了最小化MSE,训练得到的理想的数据是整体来说更稳妥的,少了一些激进的数值,从而在生成图像边界的时候现得束手束脚,导致边界部分的模糊状态。而GAN则不会有这种问题。
那么,GAN激进的边界策略真的对吗?仔细看,你会发现,也不一定。哈哈哈哈哈哈啊哈。。。
不过给人以清晰的细节展现,能够更大程度上讨好人的眼球。这一点,GAN做到了。
那么GAN的思想是什么呢?
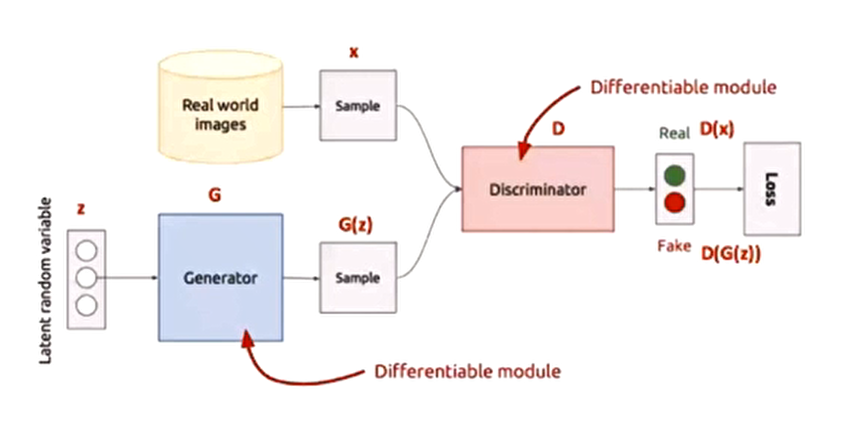
GAN的核心思想,是做生成器和判别器的对抗。生成器生成更加像原图的图片,判别器尽最大努力判别这是假的。所以这种方式被称为对抗生成。
举一个简单的例子
目前,生成器要生成一张钞票,它先手画了一张。虽然画得不错,不过判别器还是能一眼看出来这是假币。
.jpg)
生成器不服气,打印了一张人民币。判别器看不出来,于是判别器拿出了验钞机,再次证明这是张假币。

生成器再次完善了各种细节,连判别器用验钞机也验不出来了。

此时生成器出师了,可以执剑闯天涯了。
由此我们可以将GAN的思想用公式表达出来
.jpg)
整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G的目的:G应该希望自己生成的图片“越接近真实越好”。
D的目的:D的能力越强,D(x)应该越大,D(G(x)应该越小。这时V(D,G)会变大。因此式子对于D来说是
求最大(max_D)
式子中,为了前期加快训练,生成器的训练把log(1-D(G(z)))换成-log(D(G(z)))
看看这一个min一个max,有没有对抗内味儿了。
GAN的核心代码
.jpg)
可以看到,循环了k次,第一个式子是更新生成器,第二个式子是更新判别器。
这是一个生成器的例子

可以看出,这个生成器完成了一个将7 * 7的图片拉伸成28 * 28的任务。
这是一个判别器的例子

这里做了一个二分类任务,用于判断正负样本。
那这么说的话,GAN就没有缺点吗?
当然不是。相反,原生GAN的缺点非常多:
无法加入约束条件
特别容易陷入局部最优解
G、D相互之间成长必须要同步
过于自由,不可控性太强
特别特别容易崩溃
当然这些只是冰山一角
为了区缓解这些问题,有人提出了CGAN、DCGAN、ACGAN、infoGAN、WGAN……
还有GAN在NLU方向上的应用,做文本生成等等…
不过这是后话了,有机会再聊!



