FM因子分解机?
FM是用于预估CTR的经典模型,比较善于处理稀疏数据。
为什么是FM?
先说咱比较熟悉的线性回归(一说逻辑回归,即套不套Sigmoid),线性回归可写成下面这样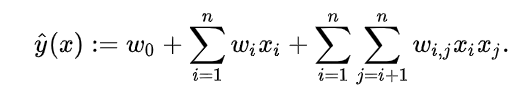
可以看出,一个特征对应一个参数。好处很明显,可以适应比较稀疏的数据等。坏处呢?不能很好地描述各个特征之间地关系。这是很重的数据,我们可不能没有它。那么我们让各个特征来做个交互吧!
看上去不错!但是在遇到一些稀疏的id类特征时,xi与xj的乘积为零,也就无法更新梯度。所以,我们需要一个更好的方式来表述特征之间的交互。
由此引入FM。
FM分解了什么因子?
仅考虑二阶特征组合的话,FM模型表达式可以写为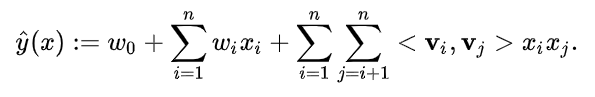
我们可以通过矩阵分解的手段,将矩阵拆分为两个向量。
在分解评分矩阵中,我们将一个rating矩阵分解为两个又多个隐向量构成的user矩阵和item矩阵。每个user和item都为各自矩阵的一个向量,向量的点积为打分。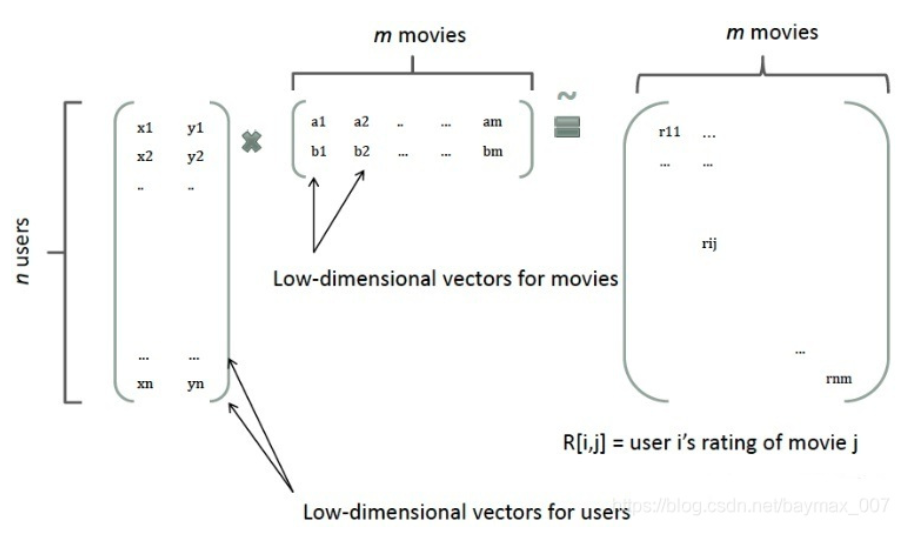
在FM中,vj即是第j维特征xj的隐向量,而xi和xj的交叉项系数是vi,vj的内积,即wij变为了<vi,vj>。
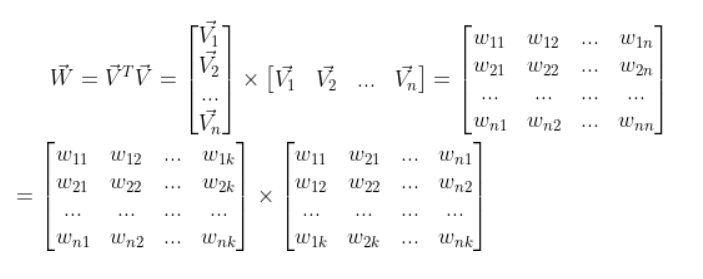
如此一来,两个向量参数分别更新。之前需要两特征都不为零,才可以更新梯度。而现在,只需要一方不为零,另一方在要求范围中的任意特征不为零即可。
这样便缓解了参数更新困难的情况。



