为何是TDM?
对大量商品做用户的个性化推荐,需要拿到用户和物品的相似度,最直接的办法就是挨个比较相似度,但是这样任务量太大,因为数量很大,所以采用矩阵分解的方式,分别计算user-vector和item-vector,用KNN找出最优解。
但是由于计算成本过高,在收集更多用户和商品特征的交互上做得不好,因为一旦要计算每对用户和物品的特征交互,那就又成了挨个遍历了,比如神经网络(???)
所以提出一种树的搜索方式,分层处理,从粗到细,召回要做多分类任务,类别数就是商品总数,用该方法后,每层类别减少,减少比较次数,所以模型可以考虑更多user-item的复杂交互。
一般说,树的搜索效率比遍历高是logn。
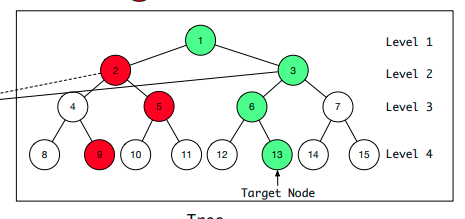
树中的每个叶子节点对应一个item,非叶子节点表示一个类别,越往上类别越宽泛,每个节点都可以映射为一个embedding。
如何构建树呢?
如果每个节点已经有embedding,则用聚类分开。如果没有embedding,就按属性类别分开。
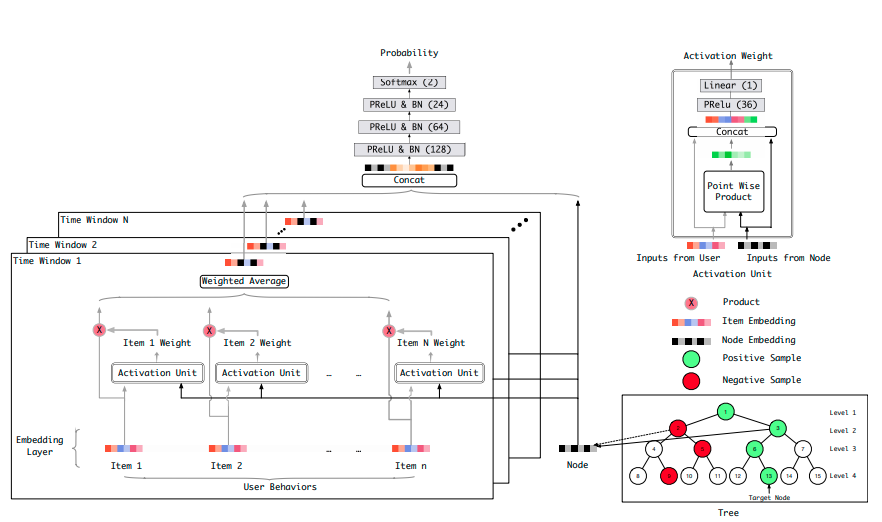
先从level1开始,将level2中每个节点的embedding分别接入左边的模型,计算出一个概率值,谁大选谁,依次往下,最终选出物品。
(做细分到每个物品很慢,也可以写几层,最后一层和K近邻结合)
如何计算概率呢?
关于计算概率,α(j)是做归一化,p(j)(n|u)是用户对某节点感兴趣概率(通过用户embedding和物品embedding输入模型计算得到),所以p(j+1)(nc|u)是用户对树中某节点的子节点感兴趣的概率,即概率最大子节点再做归一化。
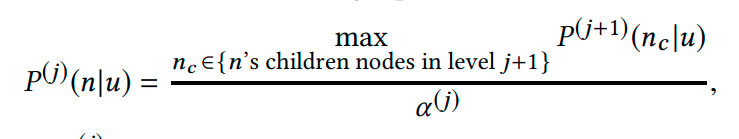
不同的window将用户的行为序列按时间拆分。
用户对应的embedding和节点embedding输入模型交互,提炼出更多的交互信息,这样即解决了KNN的难以获取交互信息的问题,也不用遍历所有item。
关于样本
再说样本,要有正样本,也要有负样本,正样本就是用户最终选择的物品所对应的树的路径。负样本是在每层都随机抽一个不是正样本的节点。
啰嗦一句
当然,既然做成树了,精度必然会有损失,比如某个概率值很低的节点的最底下的叶子节点是符合用户行为特征的,只是其它的太不符合,压低了上方节点的概率,作为宁可错杀,绝不放过的召回任务,这么做有点可惜了。但是即使是这样,也是要比聚类好上不少。



